集群运行Numpy程序的测试实践与注意事项
你正确安装Numpy了吗?
本测试主要使用的是某Numpy为底层的计算包,任务的核心在于求解矩阵对角化,使用的是LAPACK。计算的大头在于500次尺寸约为60000×60000的稀疏矩阵对角化计算。
从不同渠道安装的Numpy,其所使用的LAPACK优化可能并不一样,在不同的硬件上性能表现也大不相同。常见的优化有MKL、OpenBLAS和ATLAS,其中通常说来Intel的CPU上跑MKL会更快一些。
一般来说,不考虑指定渠道,默认情况下
conda install numpy
从Anaconda下载安装会根据你的CPU自动选择,若是Intel则用MKL,若是AMD则用OpenBLAS。当然,你可以切换到conda-forge之类的去指定版本。
如果使用pip安装,
pip install numpy
则一律是OpenBLAS。
MKL的插曲
测试最初采用MKL版Numpy计算,通过环境变量MKL_NUM_THREADS这个环境变量设定不同的核数控制多线程计算(这是使用Numpy等存在隐性并行的库都需要注意的,参考常见问题-作业运行时实际占用CPU核数过多),在同一队列提交多个独占节点的计算任务。
MKL大多数情况下都比OpenBLAS快,即便是在AMD平台上也有传说中的MKL_DEBUG_CPU_TYPE=5可以强开对MKL的支持。
但是,本次测试却出现了非常有趣的现象:
通过eScience中心的监控系统查看节点计算情况,发现大多数进程都陆陆续续计算完毕,平均在40分钟左右;而少数任务,例如最初申请了16核,突然在40分钟前后发现线程数急剧减少至单核或少量核,出现“一核有难,多核围观”的经典场面,内存也被释放掉了。但是主要的计算阶段仍然没有输出计算结果说明并不是核心计算完成陷入单线程无法结束的问题。
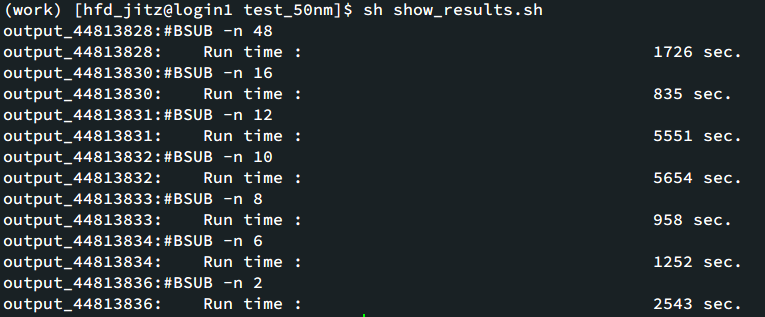
最终计算完成的时间统计也剧烈起伏。经过网上的一通搜索,并未发现很多案例。作为猜测,将其它的LAPACK优化库限制核数加入,都没有改善。更换AMD队列,仍然是同样的问题。也就是说,这个情况的出现与是Intel还是AMD的CPU没有关系。
然而最终,尝试性更换至OpenBLAS版本Numpy,发现问题神奇地解决了。
多核情况测试
由于MKL版本的神秘BUG,后来的测试通过OpenBLAS版本进行。多核计算单个任务的总耗时结果如下:
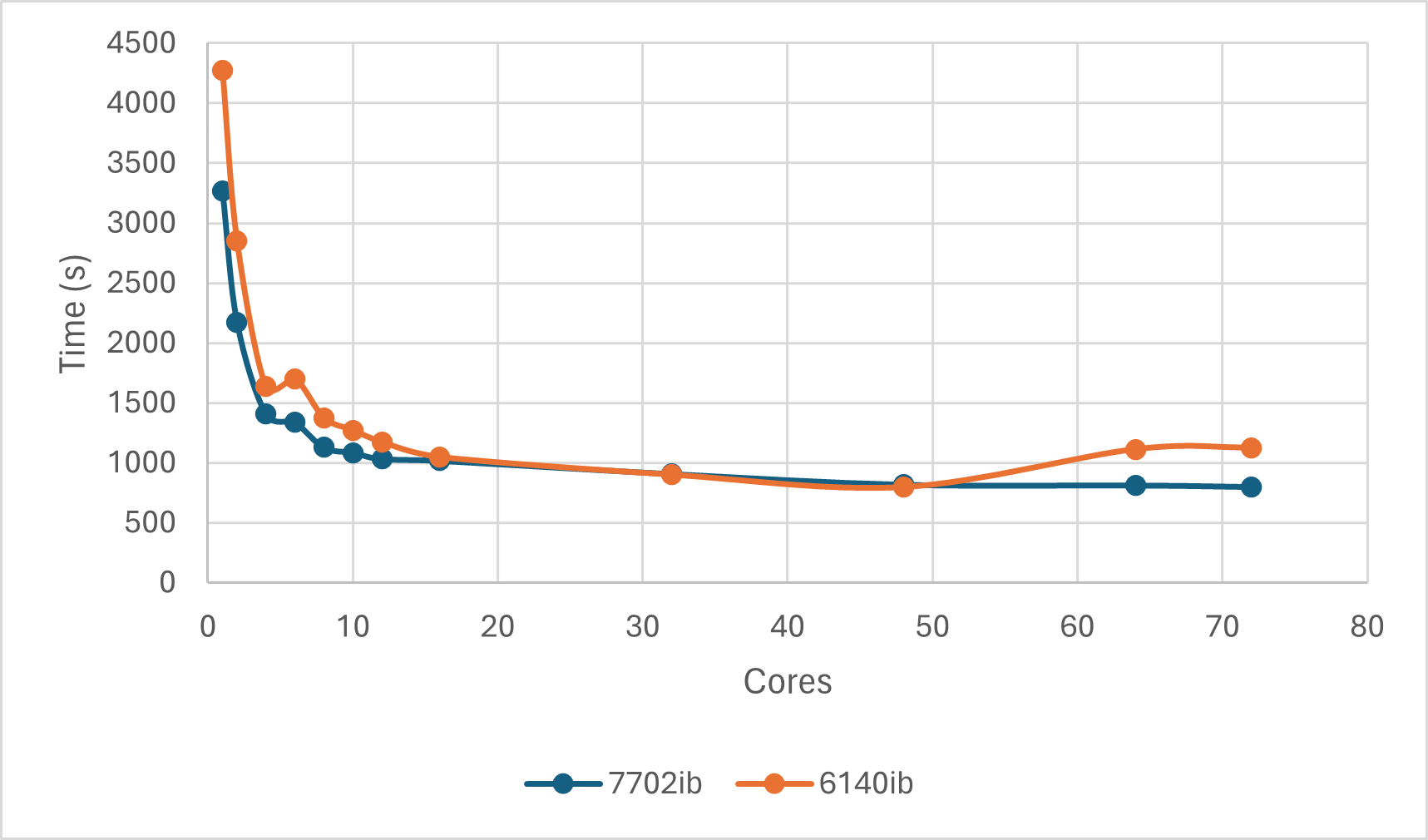
可以发现,OpenBLAS版Numpy的计算在7702ib队列和6140ib在48核以下的趋势类似,但高于48核不太一样。7702ib队列上核数越多相对而言加速的趋势一致;而6140ib队列上,核数越多反而可能会有加速效果的下降。但由于7702ib的核数更多,因此并不能排除核数大于72时也会有类似的情况。
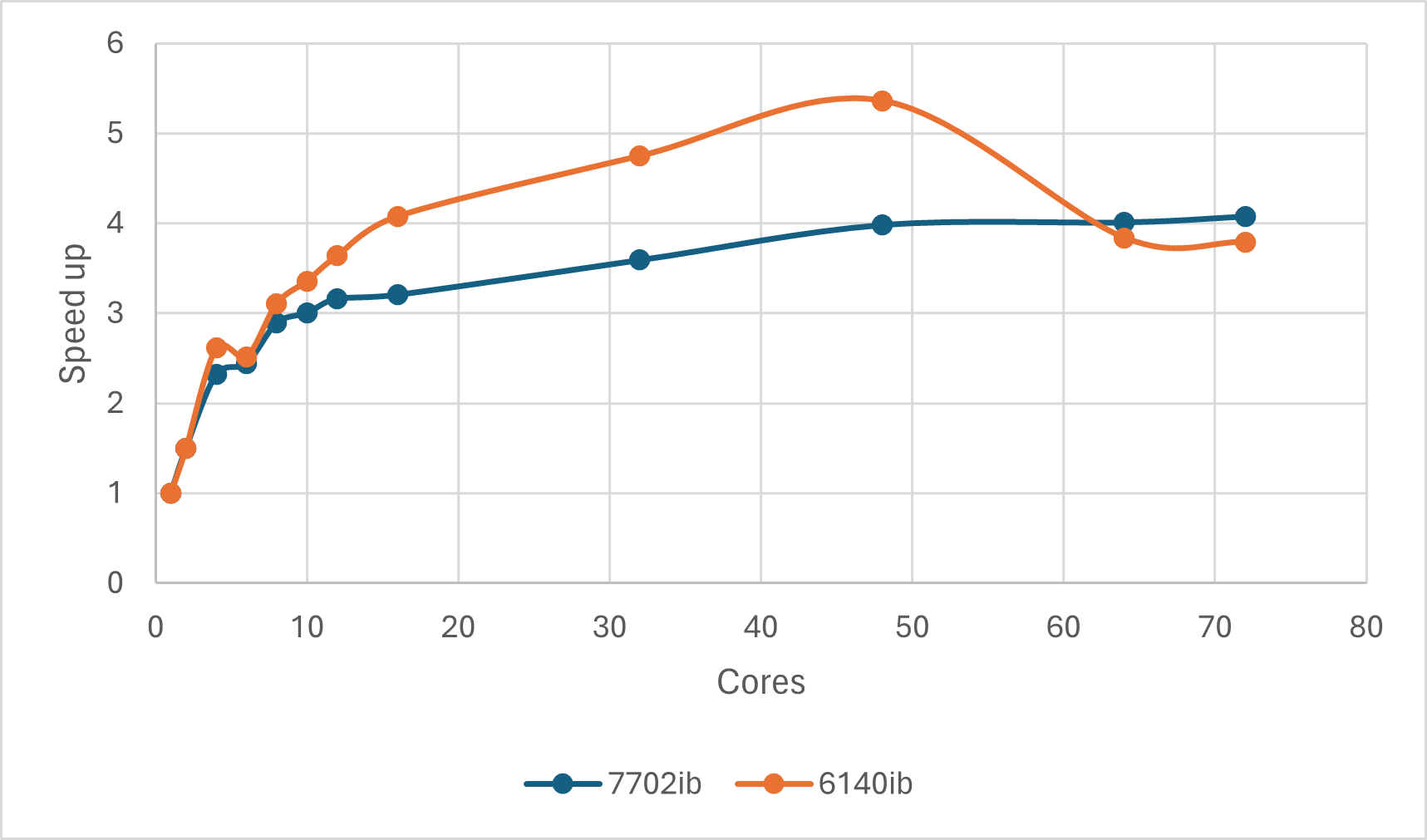
从加速比(相对串行计算的时间比值)来看,对于本测试任务,OpenBLAS Numpy的加速比极限约为4~5倍。
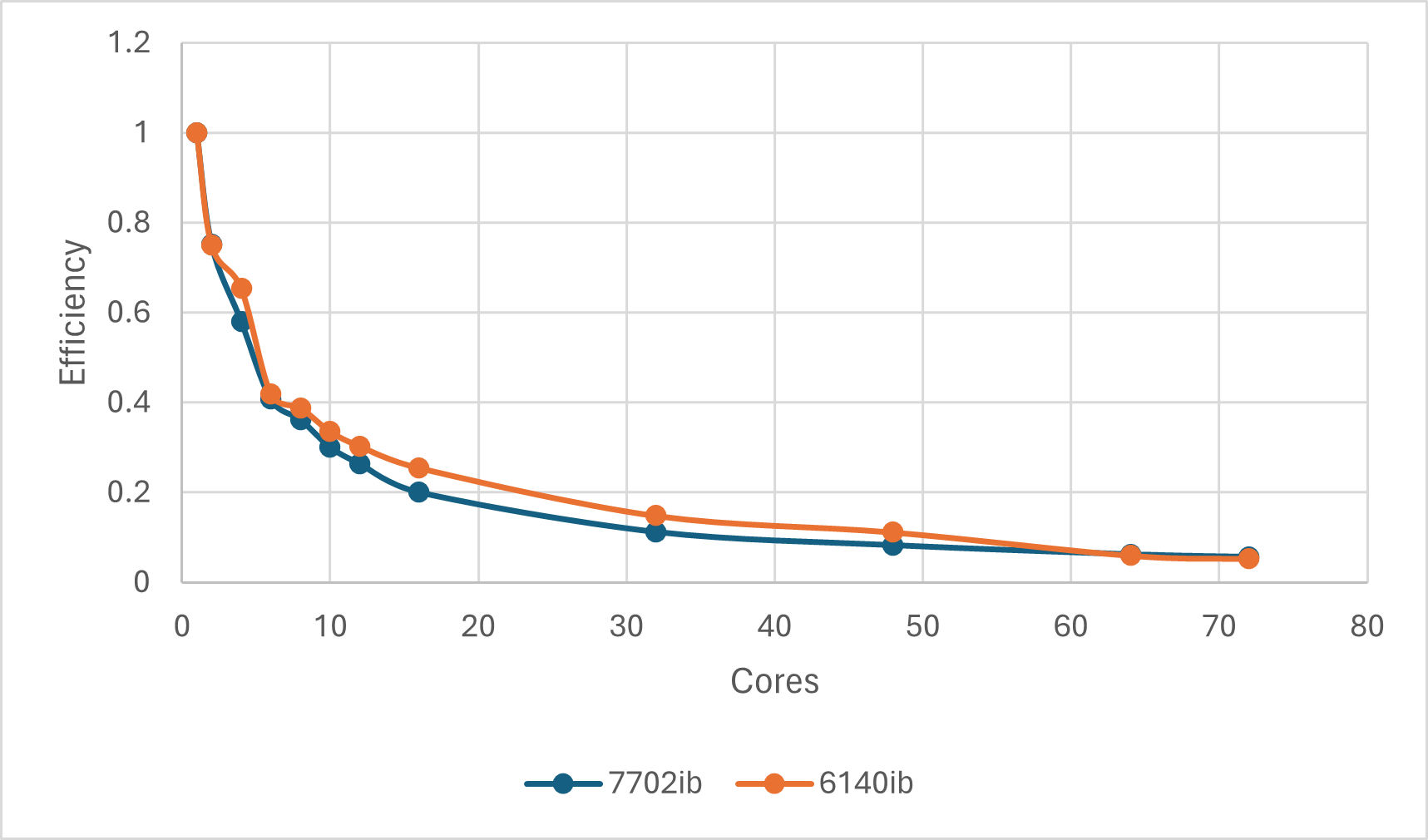
并行效率(相对串行计算的时间比值再除以核数)则随核数增多衰减极快,16核往上效率极低,全靠数量取胜。
投放任务的策略
对单个任务来说,我们只关心这一次计算的时间,因此时间肯定是越短越好。但是往往时间和核数(准确来说是申请CPU乘以时间)影响计算费用,因此计算核时的指标额外决定了是否划算。根据收费办法我们可以画出实际的花费。显然有些队列上有时候申请过多的核并不一定是划算的,这也是做基准测试的意义所在。
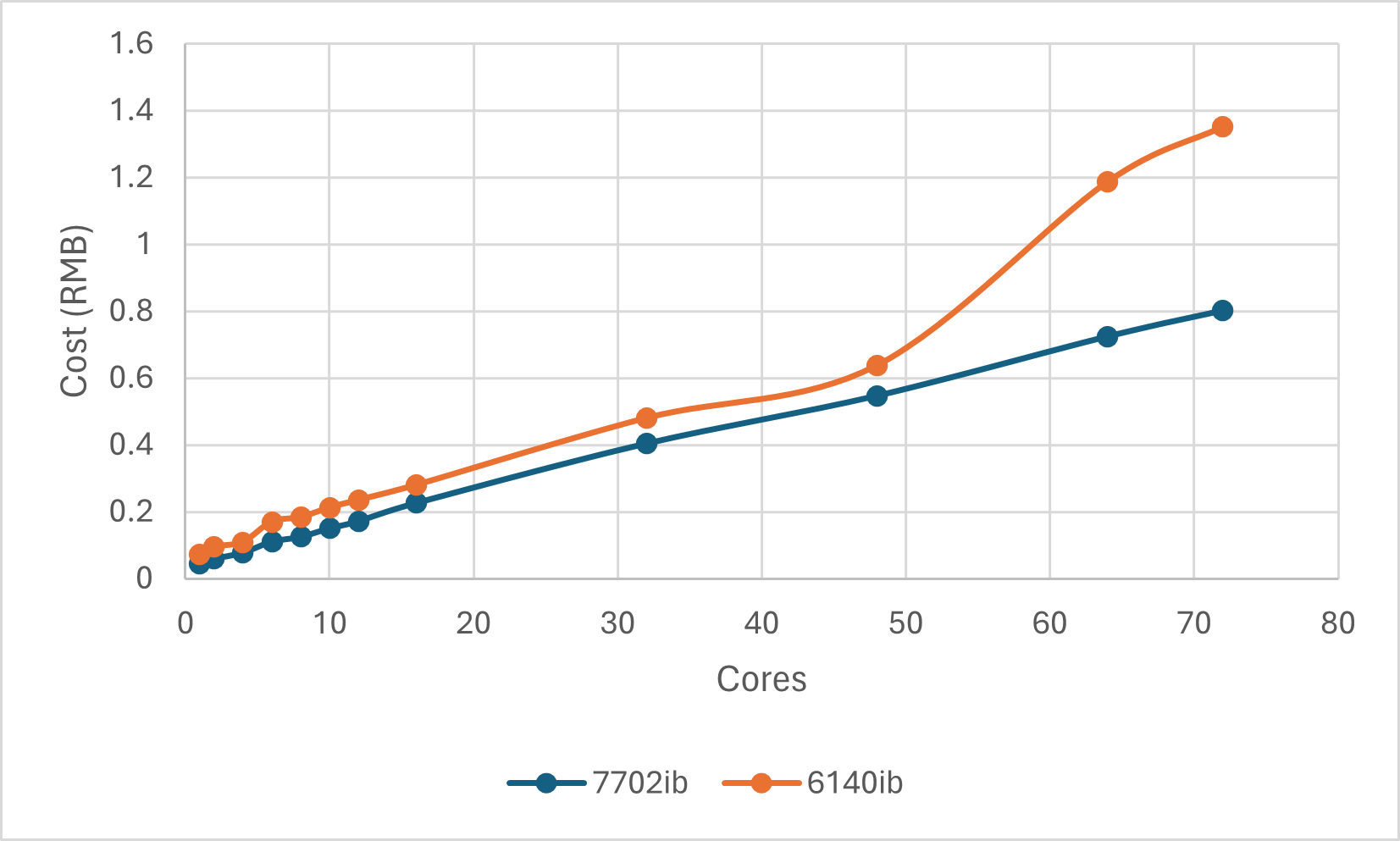
更多时候,我们可能面对的是多个计算量相当的任务,只是计算参数不同。这种情况下,我们可以根据下列公式计算:
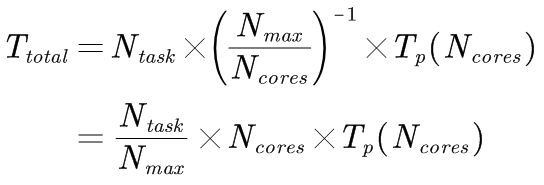
其中,N_task 指的是总任务数,N_max指的是考虑申请的总核数,N_cores指的是单个任务申请的核数,T_p是单个任务并行计算的耗时,与单个任务申请的核数有关系。N_cores与T_p相乘即为单个任务的计算核时。
可以看到,总的核时(T_total乘以N_max)也和上文的单个任务类似。
单从性价比而言,不同的核数下,我们对单个任务每加速一倍花了多少钱,也可以算出:
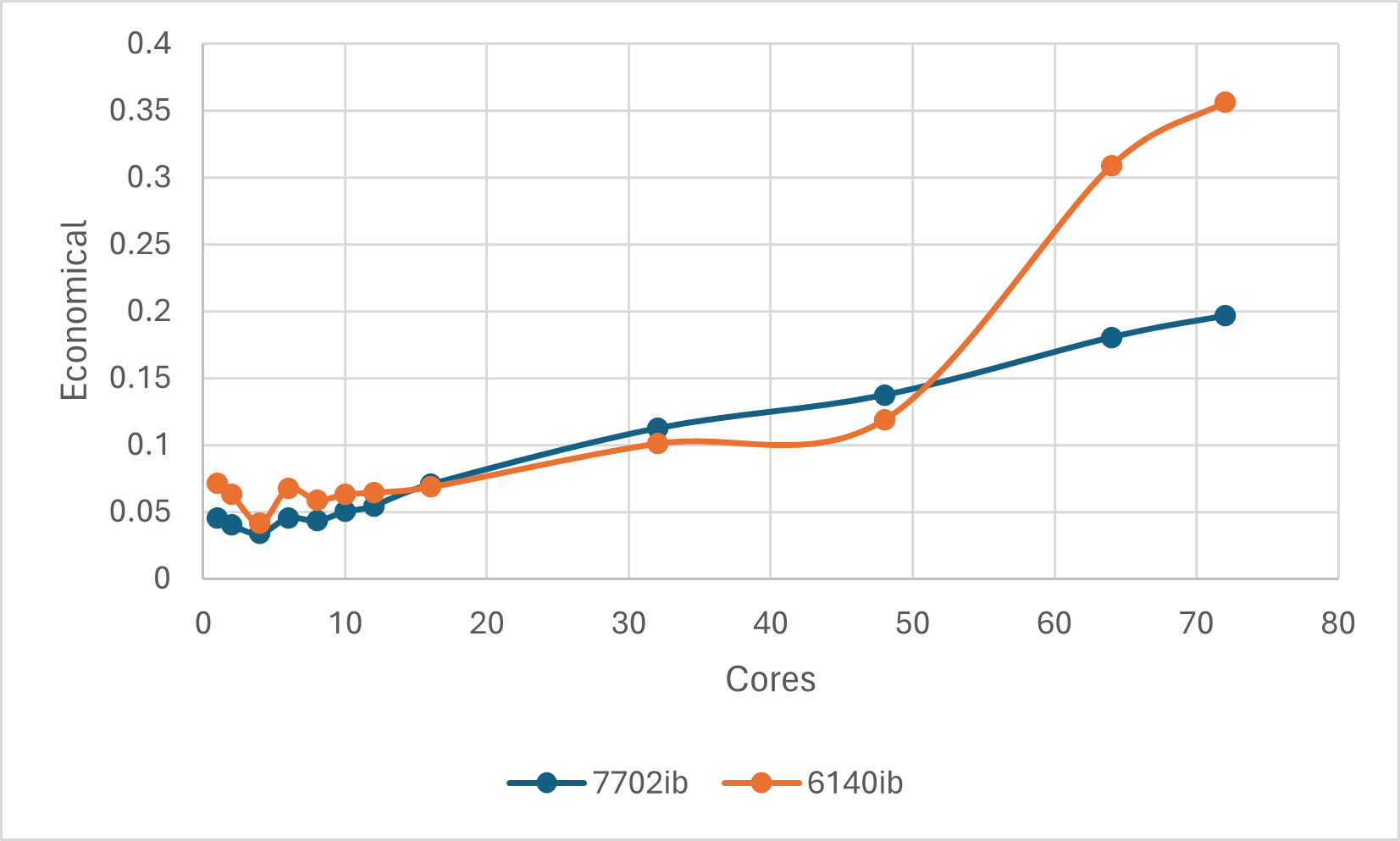
对于Numpy(OpenBLAS)计算本任务而言,性价比最高的莫过于4核。因此综合考虑时间、性价比,4核是个不错的选择。
总结
本次尝试使用集群对Numpy计算进行加速。在尝试过程中,发现需要注意几个问题:
- Numpy(并行版本)是隐性并行,所以也需要有特定的环境变量来控制与申请核数匹配,不然会被作业监控杀掉。
- 基于MKL版Numpy或者调用Numpy的计算包计算时,出现了突然任务变慢的情况,而且会长时间不结束。这与LAPACK优化库(MKL或OpenBLAS或者其他)同当前计算包的兼容性可能有关系,如果发现类似情况,可以尝试排除此类软件依赖的数值计算库是否存在这样的不同优化(甚至编译方式)的区别。
- Numpy的并行计算存在一个加速效果的上限,对本次测试的任务来说约为4~5倍。从时间、性价比的角度来说,并非核数越多越划算,例如本任务中,较为经济而且时间可接受的一个合理范围为4~16核,其中4核最具性价比;对单个任务,其花费可能尚可,但是日积月累也许是笔不小的数目。