Gromacs
注意:为了保证GPU性能, 在没有特殊要求的情况下,请使用2021版本的Gromacs,并用GPU计算所有的相互作用。没特殊要求的话请看第三部分。
1. Gromacs-2018.8
说明:
Gromacs使用CPU计算成键相互作用,使用GPU计算非键相互作用。
编译环境:
gcc/7.4.0
cmake/3.16.3
ips/2017u2
fftw/3.3.7-iccifort-17.0.6-avx2
cuda/10.0.130
软件信息:
GROMACS version: 2018.8
Precision: single
Memory model: 64 bit
MPI library: MPI
OpenMP support: enabled (GMX_OPENMP_MAX_THREADS = 64)
GPU support: CUDA
SIMD instructions: AVX2_256
FFT library: fftw-3.3.7-avx2-avx2_128
CUDA driver: 11.40
CUDA runtime: 10.0
测试算例:
ATOM 102808(464 residues, 9nt DNA, 31709 SOL, 94 NA, 94 CL)
nsteps = 25000000 ;50 ns
eScience中心GPU测试: 所有GPU节点使用单个GPU进行模拟。
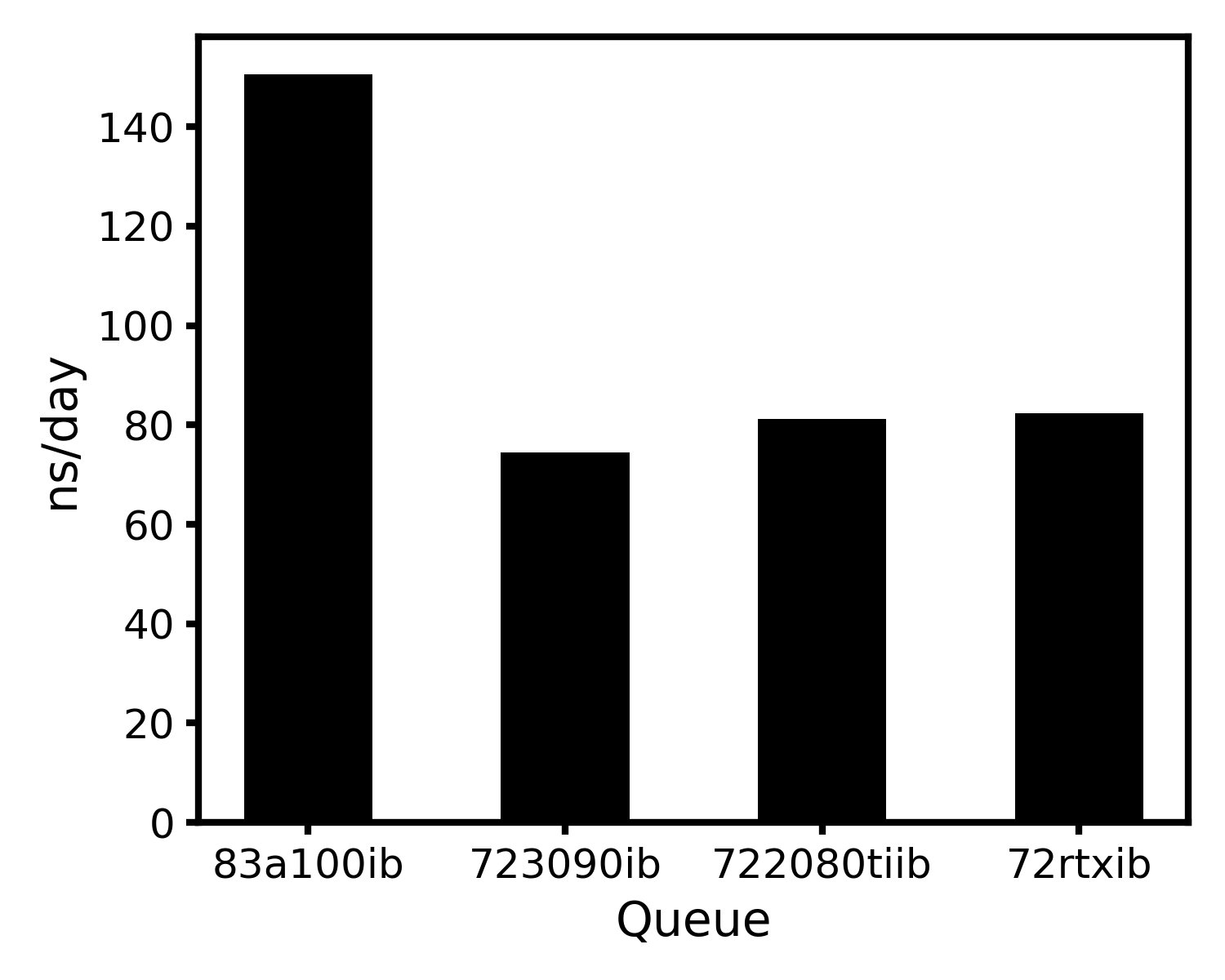
2. Gromacs-2021.3
说明:
使用的是集群自带的容器化(singularity)的gromacs-2021.3. Gromacs使用CPU计算成键相互作用,使用GPU计算非键相互作用。
文件位置
/fs00/software/singularity-images/ngc_gromacs_2021.3.sif
提交代码
#BSUB -q GPU_QUEUE
#BSUB -gpu "num=1"
module load singlarity/latest
export OMP_NUM_THREADS=`echo $LSB_HOSTS | awk '{print NF}'`
SINGULARITY="singularity run --nv /fs00/software/singularity-images/ngc_gromacs_2021.3.sif"
${SINGULARITY} GMX_COMMAND
软件信息:
GROMACS version: 2021.3-dev-20210818-11266ae-dirty-unknown
Precision: mixed
Memory model: 64 bit
MPI library: thread_mpi
OpenMP support: enabled (GMX_OPENMP_MAX_THREADS = 64)
GPU support: CUDA
SIMD instructions: AVX2_256
FFT library: fftw-3.3.9-sse2-avx-avx2-avx2_128-avx512
CUDA driver: 11.20
CUDA runtime: 11.40
测试算例:
ATOM 102808(464 residues, 9nt DNA, 31709 SOL, 94 NA, 94 CL)
nsteps = 25000000 ;50 ns
eScience中心GPU测试: 所有GPU节点使用单个GPU进行模拟。
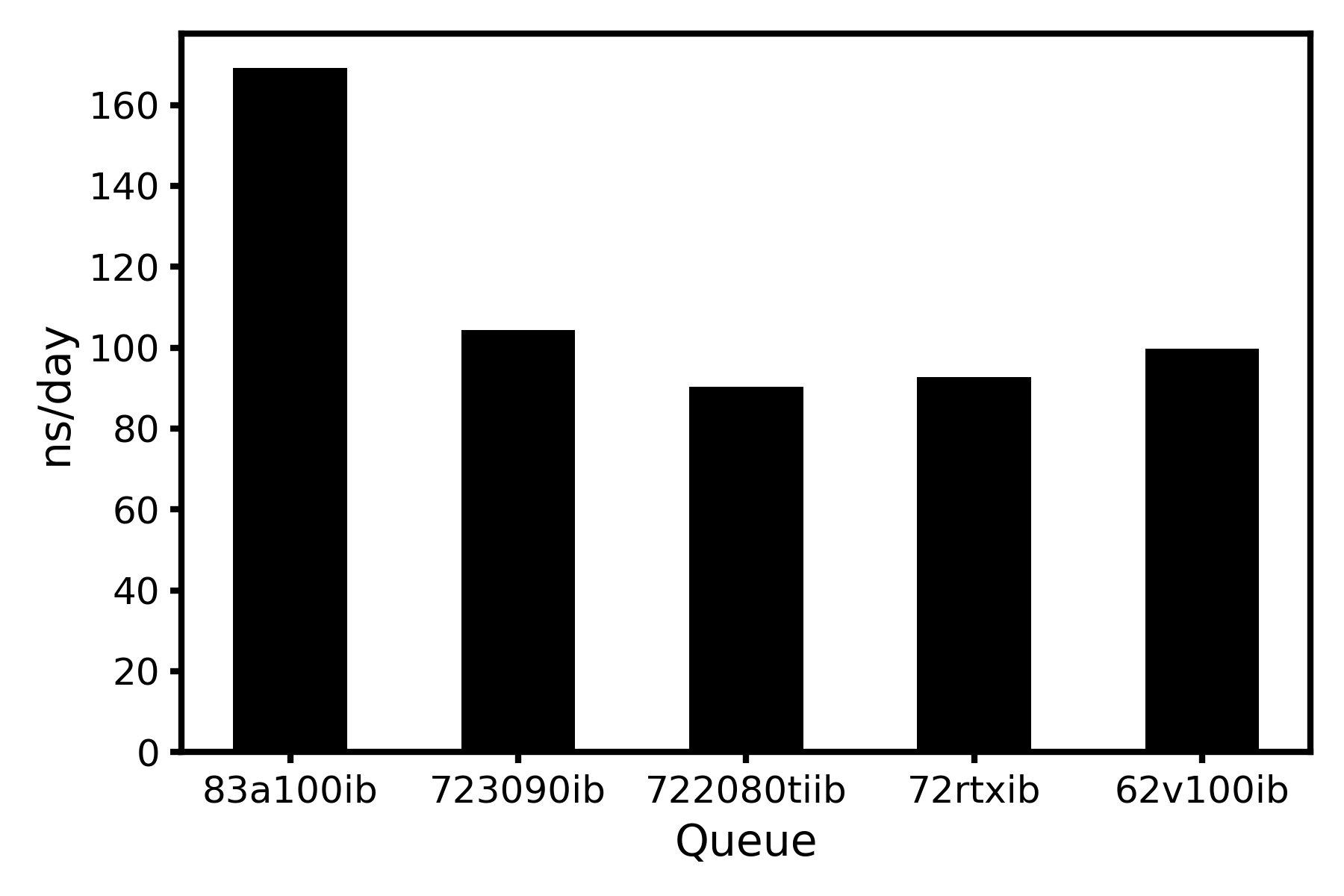
3. Gromacs-2021.3(全部相互作用用GPU计算)
说明:
由于从2019版本开始,不同的相互作用都可以在GPU上进行运算,所以尝试用GPU进行所有相互作用的运算。
文件位置
/fs00/software/singularity-images/ngc_gromacs_2021.3.sif
提交代码
#BSUB -q GPU_QUEUE
#BSUB -gpu "num=1"
module load singlarity/latest
# 需要,否则会占用所有CPU,反而导致速度边慢
export OMP_NUM_THREADS=`echo $LSB_HOSTS | awk '{print NF}'` # 需要,否则会占用所有CPU,反而导致速度边慢
SINGULARITY="singularity run --nv /fs00/software/singularity-images/ngc_gromacs_2021.3.sif"
# 设置所有的运算用GPU进行
${SINGULARITY} gmx mdrun -nb gpu -bonded gpu -update gpu -pme gpu -pmefft gpu -deffnm <NAME> # 设置所有的运算用GPU进行
结论:
- 对于GPU节点,如果使用GPU+CPU混合运算,主要限制的速度的会是CPU,所以应该尽可能使用GPU进行相互作用的计算。
补充信息
每个GPU队列带有的CPU核数
| Queue | CPU Core |
|---|---|
| 72rtxib | 4 |
| 722080tiib | 4 |
| 723090ib | 6 |
| 62v100ib | 5 |
| 83a100ib | 8 |